
Lunar Rover - Autonomous

Lunar Rover - Autonomous
A resource rover is an extraterrestrial vehicle used for space exploration as well as resource extraction on various celestial bodies.
Exploration rovers are a staple of modern space exploration, but come with a major caveat: they are dependent on constant human control. Every movement is decided upon by a human on Earth and transmitted through space – a 7-minute-long journey to reach a rover on Mars – before the rover can perform the motion. This vastly slows down exploration, and the dependence on human control limits the scale with which space agencies can deploy rovers. The Autonomous Rover team at STAC works on solving that problem. Our mission is to develop robust, artificially intelligent systems which can control a rover without human input. We are part of the larger AI Rover team, which under the guidance of NASA AMES is developing the algorithms that will be deployed on the Mechanical Rover team's physical lunar rover intended for exploration and resource extraction.
An autonomous rover system deployed on the moon could be used to mine resources. Subsurface metals and water on the moon can be used to build tools for a habitable extraterrestrial environment, and can be used to refuel rockets. However, extraction of these resources is incredibly difficult. For instance, rovers need to avoid mining in shadowed regions for extended periods of time, reroute for battery charging and storing collected resources, and communicate with each other to maximize coverage. We employ reinforcement learning as a tool to minimize the cost of extracting minerals. The software team works on simulation of the moon environment and on training reinforcement learning algorithms.
The end goal is to create a swarm of autonomous rovers that locate and extract resources on the Moon while exploring areas of the Moon that have not been studied in the past. For more info, check out our project page!

Our Software Stack
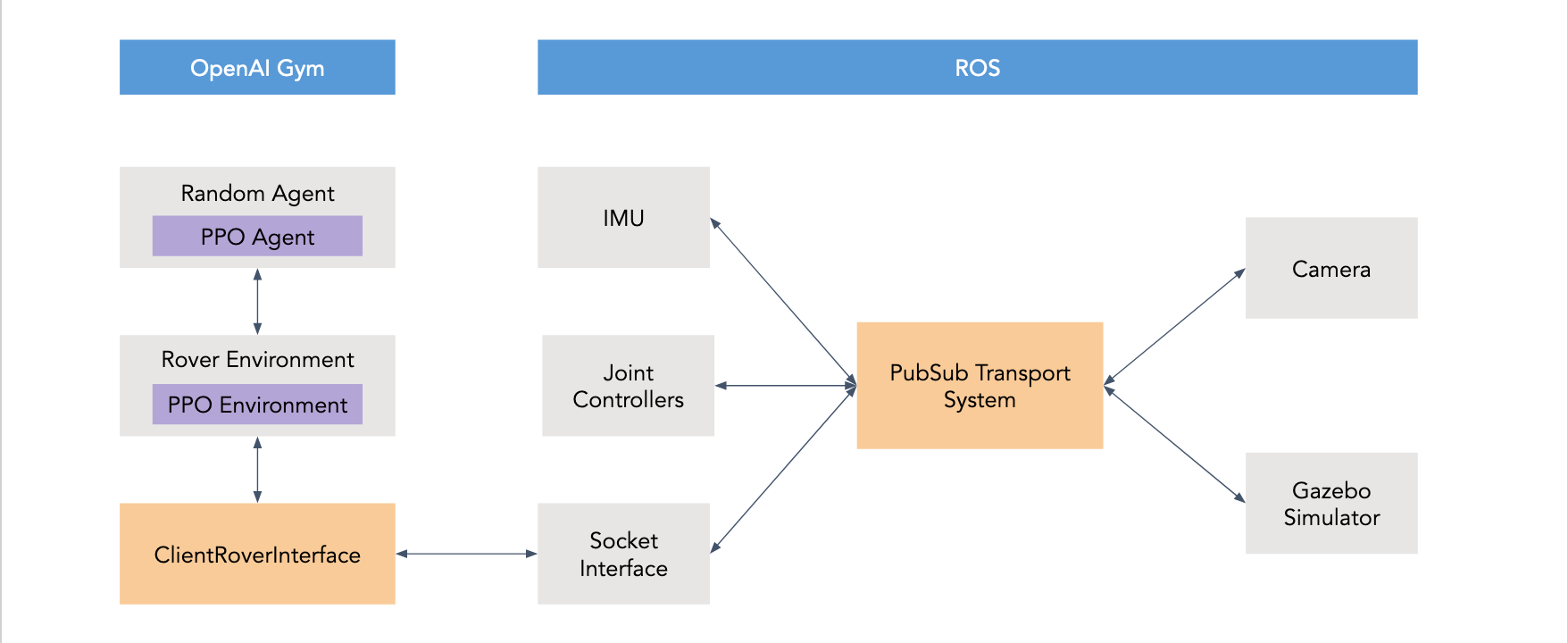
Over the last few months, the Autonomous Rover team's software division has put together an end-to-end system for testing reinforcement learning algorithms in a custom environment, built with OpenAI Gym, ROS, and the Gazebo physics simulation engine.
The Simulation
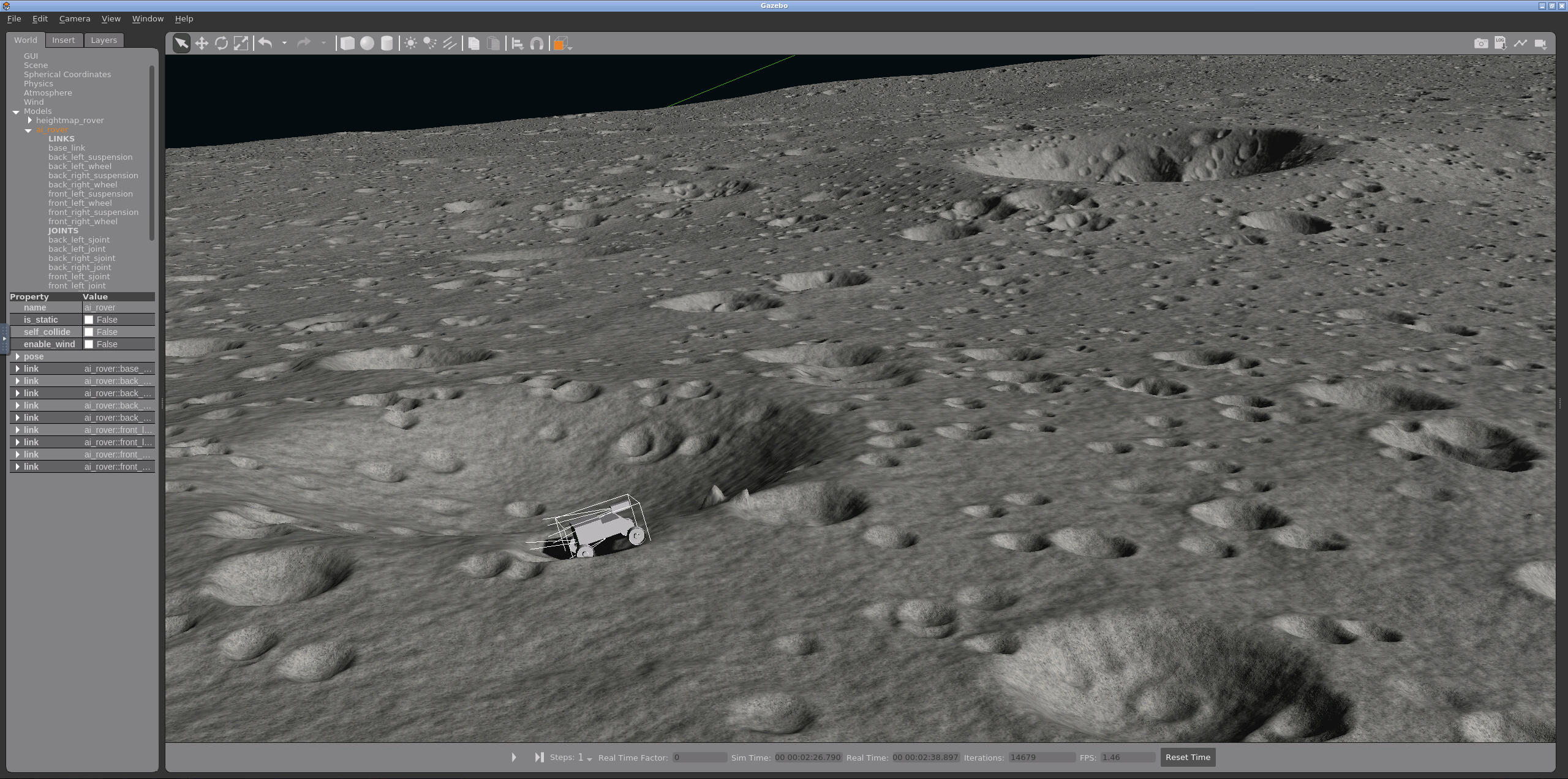
In Gazebo, we have simulation of the Moon running on one Linux machine. We use ROS as a framework for connecting the simulation with logging and input. We model the rover using a URDF generated from a CAD model. The inputs to this Gazebo-ROS system are powers to the left and right wheels and the outputs are images, position, velocity, acceleration, and joint manipulation data. The simulation is abstracted as an Open AI Gym environment so that algorithms interacting with it can be environment agnostic.
Why Containers?
The one machine setup was fine for initial development but unscalable. We needed a simulation that can be setup easily on different machines regardless of host environment. We also want to run these simulations on remote, GPU-enhanced servers for faster training and testing in the future. We turned to Docker containers. Docker allows for OS-agnostic dependency resolution and quick cluster deployment on cloud services such as Kubernetes. Communication between the simulation container and the host machine was handled by a custom socket interface.

Algorithms: Random Policy, PPO
Given a solid foundation in simulation, we turned to the algorithmic side of our project for testing. We began by formulating our rover as an agent in a Markov Decision Process (MDP) using OpenAI Gym so that we could model behaviors more easily for the context of reinforcement learning. The MDP formulation is defined by:
A) the state space, which contains a first person view of the rover as an image, gyroscope readings, and accelerometer readings
B) actions which are defined as pairs of power inputs to the two sides of the rover
C) transitions which are implicitly defined by the evolution of the physics in Gazebo
D) reward functions, which evaluate the performance of a policy based on how safe the path chosen was and how long it took
E) observations, which are currently defined as full-state knowledge of the environment.
First, we created a random policy. This policy chooses random actions to take, independent of the current state, like a random walk. We thought this was important to baseline our future policies, because in RL, it is often the case that the policies don't end up learning anything useful, and a way to quantify that is to compare the rewards of the trained policy with a baseline, in this case a random policy. Other examples of baseline policies include using A* to find optimal paths.
We implemented the Proximal Policy Optimization (PPO) algorithm, which we chose for its relevance to the task of driving in an unknown terrain. PPO is an model-free deep reinforcement learning algorithm that works in continuous state action spaces, which is necessary for generating low-level control policies. PPO has two neural networks: one is used for the policy function, with the states as the input, and the actions as the output, and the other is used as a value estimator to estimate what the total reward the rover can obtain from starting at the current state and acting according to the policy. This value function is used to determine the “advantage” of an action, or to rank the actions in terms of how well each one will do in the future.
Future Plans
So far, we have barely scratched the surface of what a rover needs to do. Our reward function can teach rovers to navigate from point A to point B, but that is just one of the many goals. We plan to add functionality to enable resource extraction: identify possible resources in recorded images (e.g. water deposits) and extract them. Once this is completed, we will create multiple rovers, having them work together as a swarm for the most efficient coverage of the Moon.